[머신러닝] 지도학습 / 보스턴 집값 데이터로 선형회귀하기 (Linear Regression)
안녕하세요 ~
이번 포스팅에서는 머신러닝 알고리즘에 대해 정리해보려고 해요!
머신러닝의 종류에는 (1) 지도학습 (2) 비지도 학습 (3) 강화학습 이 있어요.

지도 학습 : 문제와 정답을 모두 알려주고 공부시키는 방법 ex) 개와 고양이 학습 시킨 후 분류하기, 티쳐블 머신처럼 !
비지도 학습 : 답을 가르쳐 주지 않고, 스스로 분류하도록 하는 방법 ex) 개와 고양이 학습 없이, 기계 스스로 분류하기
강화학습 : 기계가 문제를 풀이하면, 보상을 줌. 보상을 통해 상을 최대화하는 방향으로 행위를 강화하는 방법

이번 포스팅에서는 지도학습 중에서 단순 선형회귀만 다루도록 하겠습니다.
[개념]
- 선형회귀 : Linear Regression
- 데이터를 가장 잘 대변해주는 하나의 선을 찾아내는 것 (y = ax + b)
- 집 크기와 집값간의 상관관계를 나타내는 데이터가 있다고 가정, 그 데이터를 잘 대변해주는 선을 찾는 알고리즘
- 이러한 선을 최적선이라고 하며, 우리의 목표는 최적선을 만들기 위한 a와 b의 값을 찾는 게 목표 !
- 변수, (1) 목표 변수 : 우리가 맞추려고 하는 대상 (2) 입력변수 : 목표 변수를 맞추기 위해 사용하는 인풋
- 집 크기에 따른 집 값을 예측하는 모델이라면, (1) 목표 변수 y = 집값, (2) 입력 변수 X = 집 크기
- 평균 제곱 오차(mean squared error), 실제 값과 예측값 간의 차이를 제곱해서 평균 낸 것 ! => 오차를 파악할 수있음
[모듈, 데이터셋 불러오기]
: 우리가 사용할 데이터는 보스턴 데이터 집값, 사이킷런에서 제공하고 있는 데이터 중 하나이다.

우선 사이킷 런이 설치되어 있지 않다면 %pip install 로 사이킷 런 설치
필요한 모듈은 다음과 같다.
from sklearn import datasets #사이킷런에 있는 데이터들을 사용하기 위한 모듈
from sklearn.model_selection import train_test_split #훈련 데이터와 테스트 데이터를 나누기 위한 모듈
from sklearn.linear_model import LinearRegression #선형회귀를 하기 위한 모듈
from skleanr.metrics import mena_squared_error #평균 제곱 오차를 구하기 위한 모듈
datasets.load_boston()을 통해서 데이터를 불러오고, 이를 boston_house_dataset에 저장한다.
But, 지금은 윤리적 문제로 사용하지 않고 있다. 교육적 목적 아니라면 사용하지 말라는...
집 값에 영향을 미치는 요소 중 하나가 '흑인 비율'이어서 그렇다고 한다. (인종차별 ㄲㅈ)
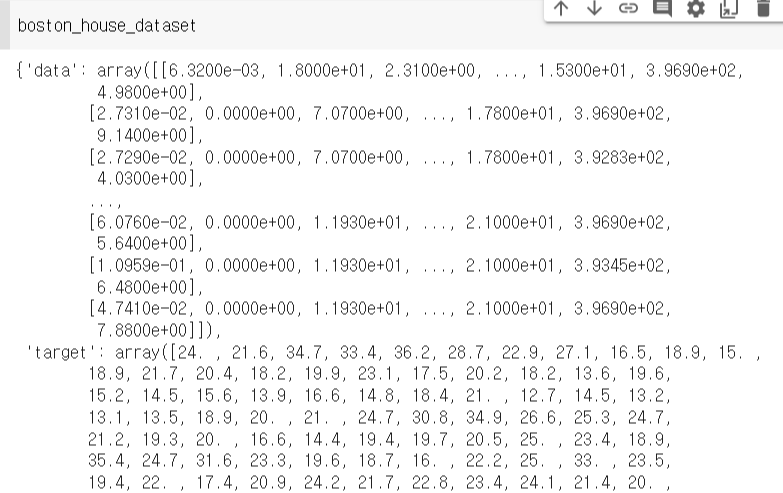
보스턴 집값 데이터를 확인해보면 다음과 같다.
지금부터 머리에 새겨야할 개념 하나를 설명하자면, 바로 'data'와 'target'이다.
'data' = the independent variables also know as X values -> 독립변수로 X값, 즉 입력변수
'feature' = the target variables or the price of the houses or dependent variables also known as y values -> 종속 변수로 y값, 즉 목표 변수 !
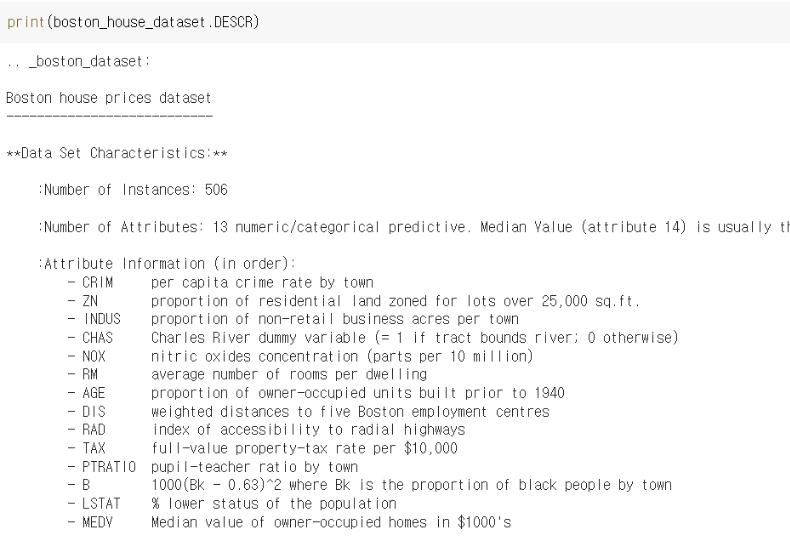

boston_house_datataset.DESCR()을 하면 description, 즉 attribute information 을 보여준다.
속성 정보, 즉 입력 변수를 알려준다고 생각하면 쉽다.
각각의 입력 변수들이 어떤 의미를 가지는지는 이 포스팅에서 설명하지 않겠다!
궁금한 사람들은 이 블로그를 참고하면 좋을 것 같다.
강의 01 보스턴 주택 가격 데이터셋 소개
보스턴 주택 가격 : 1978년에 발표된 데이터로 미국 보스턴 지역의 주택 가격에 영향을 미치는 요소들을 정리함 town 별 [https://scikit-lear ...
wikidocs.net
[데이터 프레임 만들고, X, y 정의하기]

위의 정보들의 넘파이 행렬로 되어 있어서 가독성이 매우 떨어진다. 그래서 다음으로는 데이터를 보기 좋게 가공하는 작업을 해야한다.
X = pd.DataFrame('데이터프레임으로 만들고 싶은 데이터(입력 변수)', columns = 속성이름)
y = pd.DataFrame('데이터프레임으로 만들고 싶은 타겟(목표 변수)')
우리는 'CRIM', 범죄율에 따른 집값만을 볼것이기 때문에 X[['CRIM"]]을 해준다.
[테스트 / 훈련 데이터 나누고 선형회귀 모델 만들기]

다음으로는 X와 y를 훈련 데이터와 테스트 데이터로 나누는 과정이 필요하다.
이 과정이 필요한 이유는, 100% 모든 데이터를 투입해서 모델을 학습 시키면, 이 모델이 제대로 만들어졌는지 확인할수가 없어지기 때문이다.
test_size는 몇 대 몇 비율로 훈련 / 테스트 데이터를 나눌지 정해주는 옵셔널 파라미터다. test_size = 0.2라면 훈련 데이터 비율이 8, 테스트 데이터 비율이 2가 되는 것을 의미한다.
random_state란 난수 생성에 어떤 규칙을 넣어서 동일한 결과를 나오게 할지를 결정하는 옵셔널 파라미터다. 만약 random_state에 값이 없다면 규칙 없이 결정트리를 만들어서, 사람마다 다른 결과가 나올 수 있다.
다음으로는 model 을 만들고, X_test값을 넣었을때의 y_prediction을 구한다.
앞서 말했듯이 실제값과 예측값 사이의 오차를 알기 위해서, y_prediction을 구한다.
[오차 구하고, 그래프로 확인하기]

mse = mean_squared_error(실제값, 예측값)
mena_squared 함수를 활용하면, 바로 평균 제곱 오차가 나온다.
그런데 여기서 보통 **0.5, 즉 루트를 씌운다. 즉, 평균제곱근 오차를 구하는 것이다.
왜냐하면, 평균 제곱 오차의 경우, 제곱을 하기때문에, 작은 오차라도 굉장히 크게 두드러질 위험이 있다.
또한, 제곱으로 인해 오차가 데이터의 값만큼 커지는 경우가 발생하기도 한다...!
model.score(X값, y값)을 통해서 모델의 성능을 평가할 수 있다.
보면 우리는 하나의 속성 값에 대한 모델을 만들었으므로, 성능이 보다시피 굉장히 안좋다...
다음 포스팅에서는 다항회귀를 통해서 성능을 높여보겠다.

마지막으로 멧플롯립으로 모델 확인하기.
model.coef_와 model.intercept_를 통해서, 최적선 y= ax + b의 a와 b값을 각각 확인할 수 있다.

헉헉... 이번 포스팅은 좀 길었다.
확실히 블로그 정리가 도움이 된다.
인강으로 듣고 휙휙 지나간 지식들은 내 지식이 아니었음을...